
You can run all data product refresh tasks by making multiple, sequential calls to the Jobs create endpoint. These tasks include:
- Refreshing source datasets to pull the latest data from external cloud storage into Tamr’s storage layer.
- Running the data product to update clusters and golden records, and optionally updating the RealTime search index.
- (Optional) Publishing the refreshed output to configured downstream destinations.
This example also includes a helper function to poll the status of a job to ensure success.
The code samples in this topic were built using a Jupyter Notebook.
Initial Setup: Create Helper Function to Poll Job Status
First, import the requests library to help call the APIs. Then, define the helper function poll_job.
import requests
import time
def poll_job(
job_id: str,
tenant_name: str,
tamr_api_session: requests.Session,
polling_interval_seconds: int = 30,
timeout_hours: int = 2
):
"""Example function for polling a job.
Arguments:
job_id (str): The ID of the job to poll.
tenant_name (str): the name of your tenant
tamr_api_session: A Requests Session object pointed at your Tamr Tenant
polling_interval_seconds (int): The number of seconds to wait between each API call
timeout_hours (int): The number of hours to wait for a job to complete
until giving up and declaring failure.
Returns:
None
Raises:
RuntimeError
"""
polling_start = time.time()
while (time.time() - polling_start)/3600 < timeout_hours:
r = tamr_api_session.get(f"https://{tenant_name}.tamr.cloud/api/v1beta1/jobs/{job_id}")
r.raise_for_status()
job_info = r.json()
job_state = job_info["status"]["state"]
# check current state of the job
if job_state in ['PENDING', 'RUNNING', 'STOPPING']:
time.sleep(polling_interval_seconds)
continue
elif job_state == 'DONE':
# check for error state in the job payload
if "error" in job_info["status"] and job_info["status"]["error"]:
error = job_info["status"]["error"]
error_reason = error["reason"]
error_message = error["message"]
raise RuntimeError(f"The job with ID {job_id} failed with reason: \n {error_reason}\n\nAnd message: {error_message}")
# if there is no error then it was successful so just return
return
# if we've gotten this far we've exceed the timeout
raise RuntimeError(f"The job with ID {job_id} exceed the timeout of {timeout_hours} hours.")Step 1: Refresh Source Datasets
You need to refresh all source datasets for the data product before running the data product.
Identify Sources
Identify which sources are used in the data product.
You can find the sources for data product on the Configure Data Product page, as shown below.
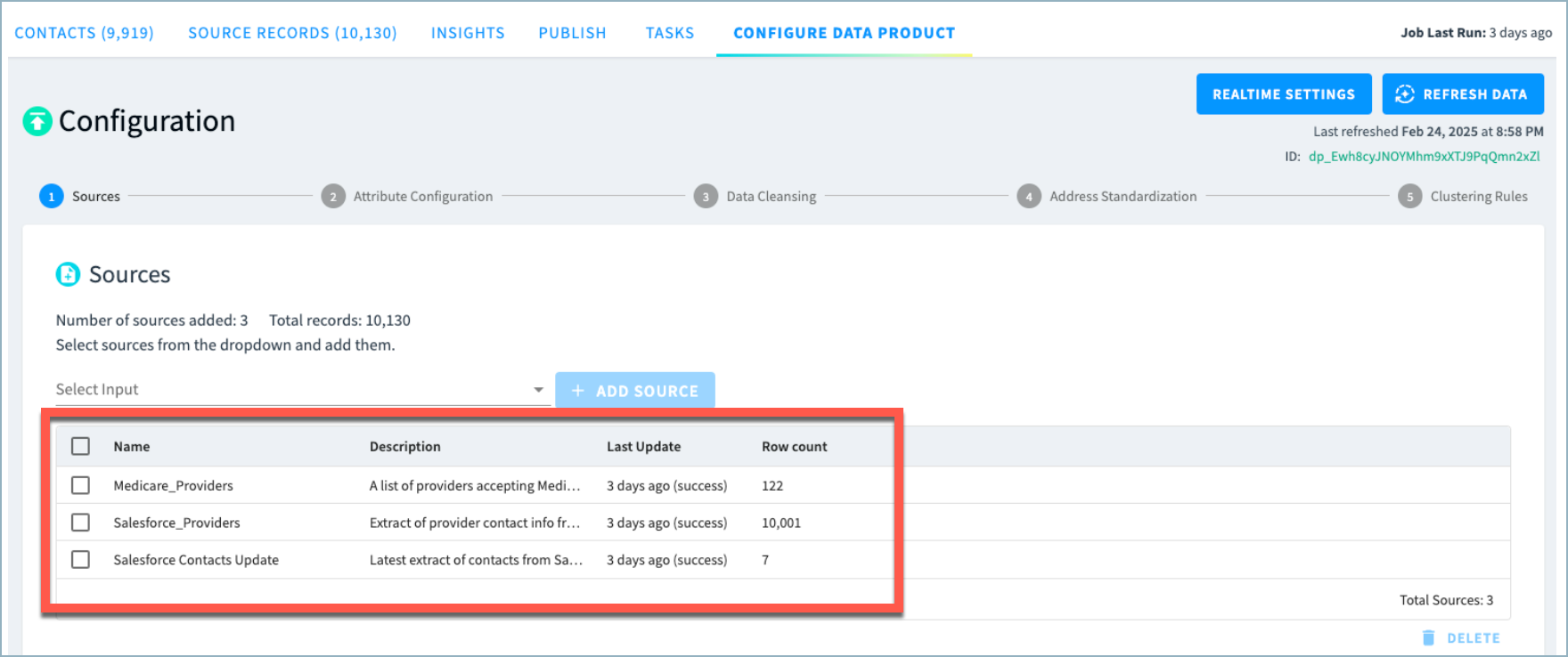
Obtain sourceId values
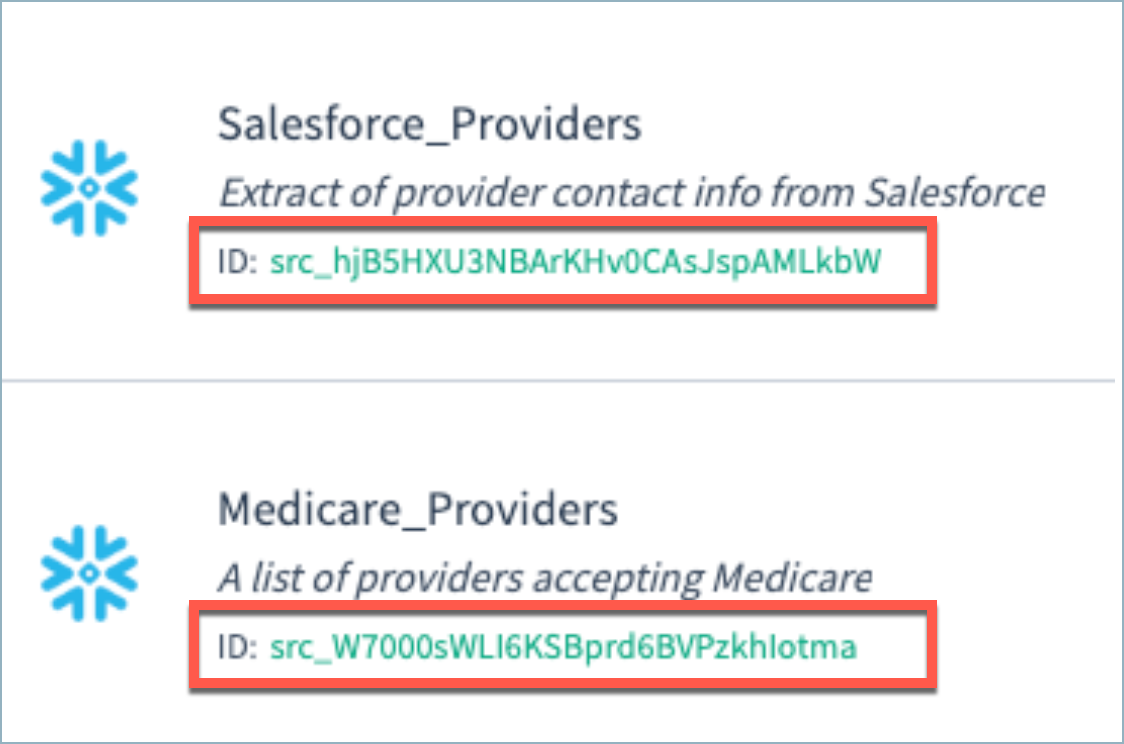
sourceId valuesNext, find the sourceId for each of these sources. These ids are available on the Configurations > Sources page, as shown below. You can select the id to copy it to the clipboard.
Define Function to Update Sources
Now that you have the sourceId values, define a function to update the source datasets by calling the Jobs API to start a load job.
def refresh_source(
source_id: str,
tenant_name: str,
tamr_api_session: requests.Session,
wait: bool = True
) -> str:
"""Example function for refreshing a source.
Arguments:
source_id (str): The ID of the source to refresh
tenant_name (str): the name of your tenant
tamr_api_session: A Requests Session object pointed at your Tamr tenant
wait (bool): When True, wait for the refresh job to finish
Returns:
the ID of the job created
"""
# craft the json payload and assert we had a successful response
payload = {"configuration": {"load": {"sourceId": source_id}}}
load_request = tamr_api_session.post(f"https://{tenant_name}.tamr.cloud/api/v1beta1/jobs", json=payload)
load_request.raise_for_status()
load_response = load_request.json()
job_id = load_response["jobId"]
# if set to wait, then wait for the job to finish
if wait:
poll_job(job_id, tenant_name, tamr_api_session)
return job_idStep 2: Refresh the Data Product and Optionally Update RealTime Search Index
After the source datasets have been refreshed, the next step is to refresh the data product output. If your data product is enabled for RealTime search, this step can optionally include updating the RealTime search index.
Obtain dataProductId value
dataProductId valueYou can find the dataProductId on the Configure Data Product page, as shown below.
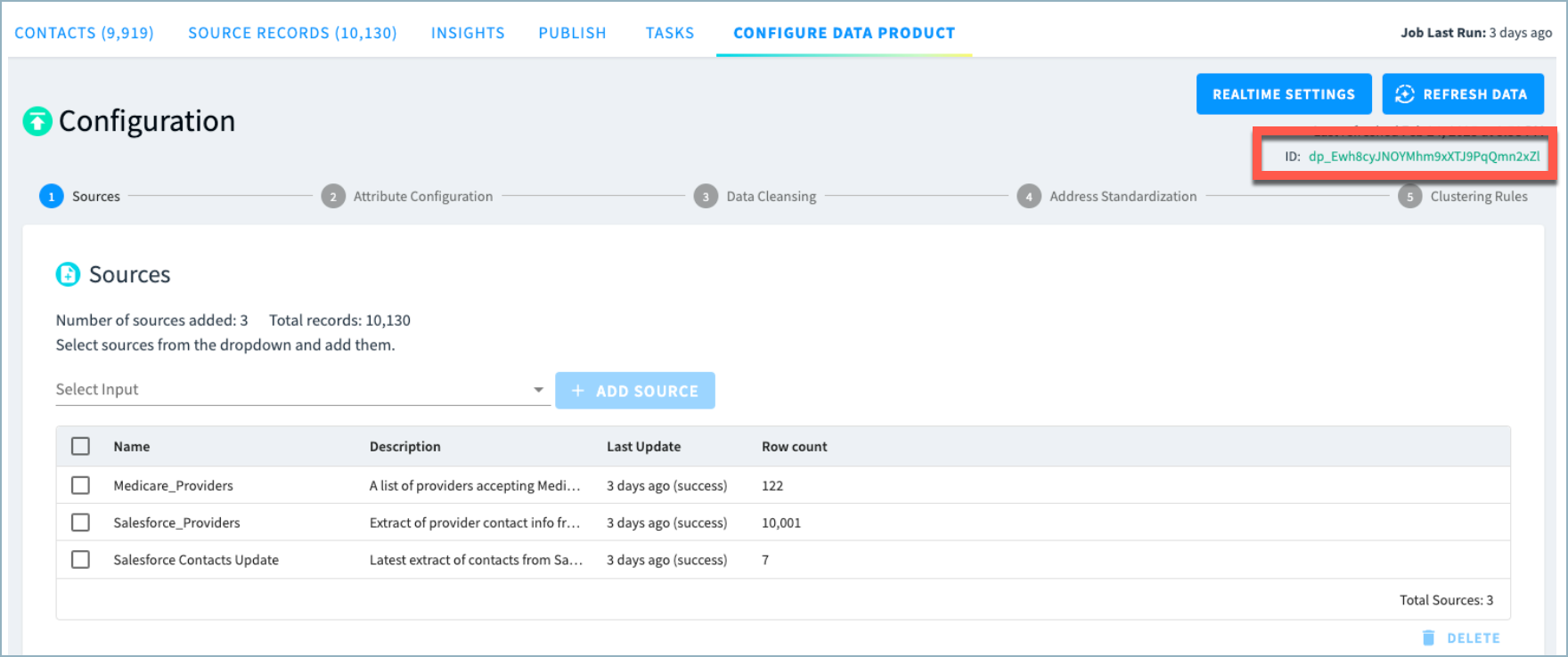
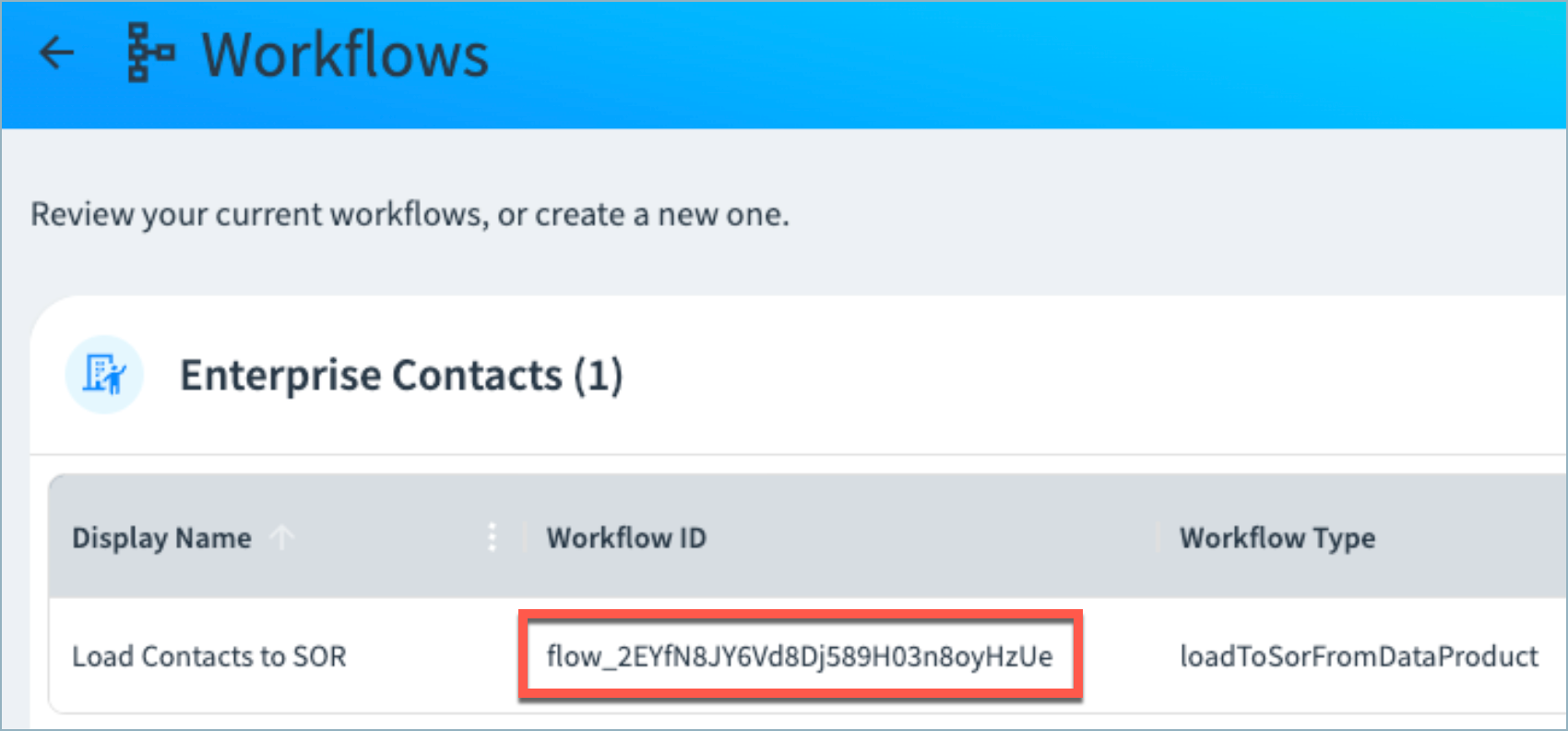
(Optional) Obtain workflowId
workflowIdThe workflowId is available from the Configurations > Workflows page as shown below. Ensure the workflow type is loadToSorFromDataProduct.
Define Function to Refresh Data Product
Now that you have the dataProductId value and (optional) workflowId value, define a function to refresh the data product and optionally update the RealTime search index.
def refresh_data_product(
data_product_id: str,
tenant_name: str,
tamr_api_session: requests.Session,
wait: bool = True
) -> str:
"""Example function for updating a data product.
Arguments:
data_product_id (str): The ID of the data product to refresh
tenant_name (str): the name of your tenant
tamr_api_session: A Requests Session object pointed at your Tamr tenant
wait (bool): When True, wait for the refresh job to finish
Returns:
the ID of the job created
"""
# craft the json payload and assert we had a successful response
payload = {"configuration": {"update": {"dataProductId": data_product_id}}}
load_request = tamr_api_session.post(f"https://{tenant_name}.tamr.cloud/api/v1beta1/jobs", json=payload)
load_request.raise_for_status()
load_response = load_request.json()
job_id = load_response["jobId"]
# if set to wait, then wait for the job to finish
if wait:
poll_job(job_id, tenant_name, tamr_api_session)
return job_id
def refresh_search_index(
workflow_id: str,
tenant_name: str,
tamr_api_session: requests.Session,
wait: bool = True
) -> str:
"""Example function for updating a RealTime Search Index.
Arguments:
work_flow_id (str): The ID of the loadToSorFromDataProduct workflow to run
tenant_name (str): the name of your tenant
tamr_api_session: A Requests Session object pointed at your Tamr tenant
wait (bool): When True, wait for the refresh job to finish
Returns:
the ID of the job created
"""
# craft the json payload and assert we had a successful response
payload = {"configuration": {"update": {"workflowId": workflow_id}}}
load_request = tamr_api_session.post(f"https://{tenant_name}.tamr.cloud/api/v1beta1/jobs", json=payload)
load_request.raise_for_status()
load_response = load_request.json()
job_id = load_response["jobId"]
# if set to wait, then wait for the job to finish
if wait:
poll_job(job_id, tenant_name, tamr_api_session)
return job_idStep 3: Publish the Output
After the data product has been refreshed, you can publish the output to a downstream system. You can publish any of the publish configurations that have been created for the data product (golden records, source records, and so on).
You need to provide both the destinationId for the publish configuration and the associated dataProductId that you obtained in step 2.
Obtain the destinationId
destinationIdThe destinationId for each publish configuration is available from the Publish page for the data product as shown below.

Define Function to Publish the Data Product
Now that you have the destinationId and dataProductId values, define a function to publish the data.
def refresh_output(
destination_id: str,
data_product_id: str,
tenant_name: str,
tamr_api_session: requests.Session,
wait: bool = True
) -> str:
"""Example function for publishing a new batch output from Tamr.
Arguments:
destination_id (str): The ID of the publish configuration to run
data_product_id (str): The ID of the data product output to refresh
tenant_name (str): the name of your tenant
tamr_api_session: A Requests Session object pointed at your Tamr tenant
wait (bool): When True, wait for the refresh job to finish
Returns:
the ID of the job created
"""
# craft the json payload and assert we had a successful response
payload = {"configuration": {"publish": {"destinationId": destination_id, "dataProductId": data_product_id}}}
load_request = tamr_api_session.post(f"https://{tenant_name}.tamr.cloud/api/v1beta1/jobs", json=payload)
load_request.raise_for_status()
load_response = load_request.json()
job_id = load_response["jobId"]
# if set to wait, then wait for the job to finish
if wait:
poll_job(job_id, tenant_name, tamr_api_session)
return job_idFinal Step: Write the End-To-End Script
Now that you have defined functions for each task, you can write a script to perform these tasks end-to-end. Note that the script below includes sample values.
We recommend following best practices for handling the API key, including not storing the key as text inside of the script.
def run_end_to_end():
# Write down the IDs we will need
source_ids = ['a', 'list', 'of', 'source', 'IDs']
data_product_id = 'dp_xyz'
workflow_id = 'flow_xyz'
destination_id = 'xyz'
tenant_name = 'my-tenant'
# for this example, and in general, we recommend waiting for each job to complete before starting the next
wait = True
# create our tamr session
tamr_session = requests.Session()
tamr_session.headers.update({'X-API-KEY': 'apk_xyz'})
# update our sources
print("Updating sources")
for source_id in source_ids:
print(f"\tUpdating source with id {source_id}")
refresh_source(source_id, tenant_name, tamr_session, wait=wait)
# refresh our data product
print("Updating data product")
refresh_data_product(data_product_id, tenant_name, tamr_session, wait=wait)
# update our search index
print("Updating SOR")
refresh_search_index(workflow_id, tenant_name, tamr_session, wait=wait)
# publish our data out
print(f"Publishing output to {destination_id}")
refresh_output(destination_id, data_product_id, tenant_name, tamr_session, wait=wait)
# success!
print("Completed updating our Tamr Pipeline!")
run_end_to_end()