
Configuring Tamr RealTime Create and Update
This topic describes how to set up and operationally run an end-to-end data pipeline using a data product with the RealTime datastore. In this use case, the RealTime datastore is used as a System of Record (SOR).
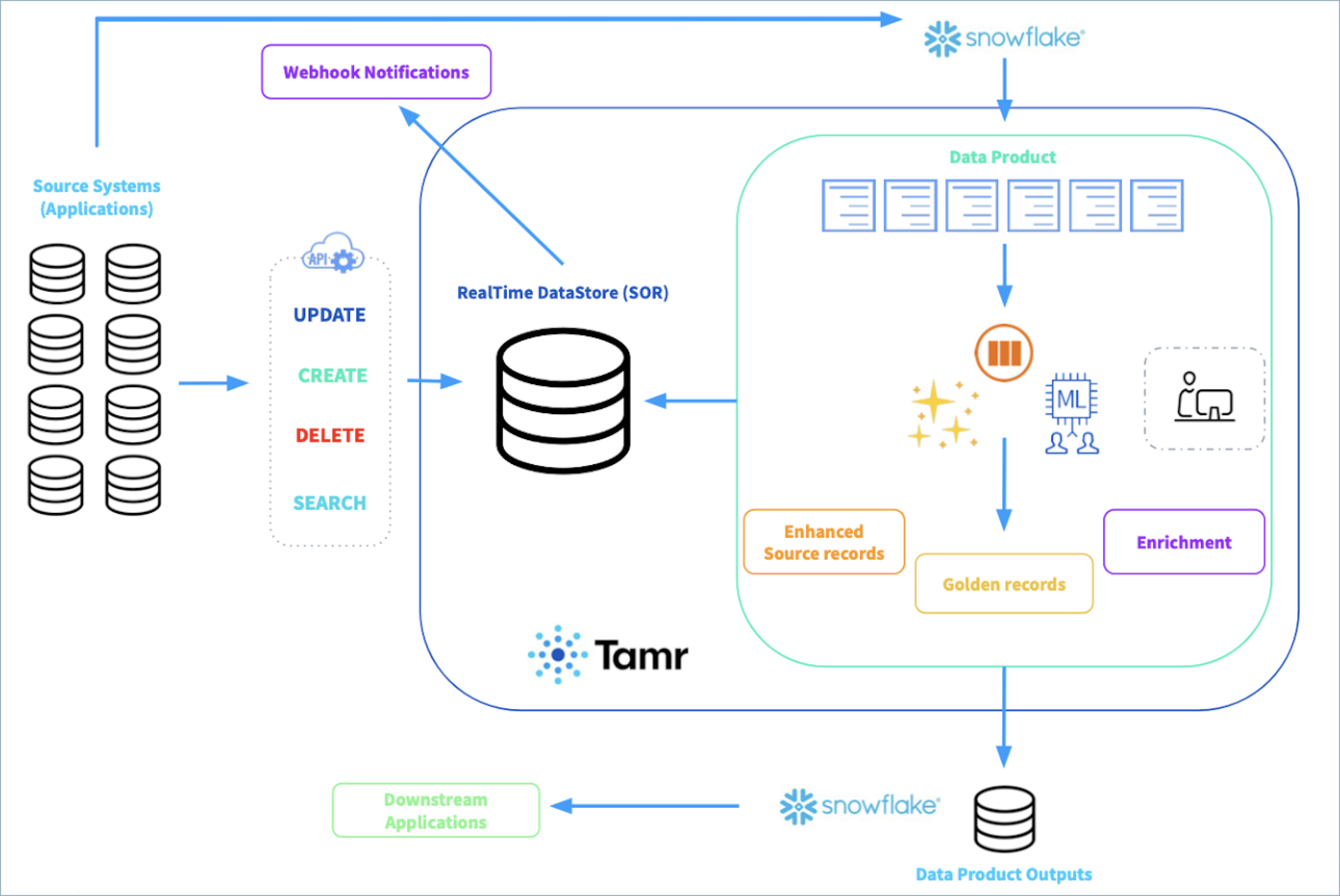
Example architecture diagram of an end-to-end data pipeline using the Tamr RealTime datastore as a SOR.
Note that diagram above includes a connection to Snowflake as an example, but you can connect to any supported cloud storage application.
Setting up and running the data pipeline includes:
- Configuring the data product.
- Publishing the data product to the Tamr RealTime SOR.
- Performing real-time actions on the SOR via API operations.
- Orchestrating the pipeline.
- Configuring a webhook to monitor authoring events.
Step 1: Configure the Data Product
Configure and run the data product, following the instructions for the type of data product you are using. If necessary, perform curation on the results.
Next, follow the instructions to setup publish configurations instructions to setup publish configurations to publish the data product outputs to your downstream applications.
Step 2: Publish the Data Product to the SOR
Configure a workflow to update the Tamr RealTime SOR with the output of your data product. Workflows calculate the events that will be committed to the SOR based on the latest data product outputs and the current state of the SOR.
Then, publish the mapping table from the SOR. This is required so that you can map the Tamr ID (tamrId )from the data product outputs with the rec_id in the SOR. Additionally, the mapping table contains:
- The version of the record (
versionId) - Time the record was created in milliseconds since the unix epoch (
createdMs). - Time the record was updated in milliseconds since the unix epoch (
updatedMs). Below is a sample schema for the mapping table output:

To configure the workflow and publish destination for the mapping table:
-
Navigate to Configurations > Workflows.
-
Select New Workflow and choose Refresh RealTime Table as the workflow type.
-
Name your workflow, select your data product, and select the table associated with your data product. (See Obtaining the Table Id.)
-
Select Create Workflow.
The new workflow appears on the Workflows page. You can run the workflow by choosing the Play icon or by using the Jobs API (see Jobs Overview).
-
Navigate to Configurations > Destinations, select New Destination, and choose RealTime Tamr ID Mapping as the destination type.
-
Name the destination, select the RealTime table, and select the connection to use to publish the data product. In the Address field, enter the table or file path to which to publish.
-
Select Create Destination.
The new destination appears on the Destinations page. You can publish the mapping table by choosing the Play icon or by using the Jobs API (see Jobs Overview).
Step 3: Perform RealTime Actions on the SOR
The use case in this section focuses on using the search then create or update record API call to create new records in the SOR. However, this pattern can be followed for any update to records in the SOR provided that the update is also made in the source record.
Requirements
New and updated records must be added to source datasets in the data product (with a stable primary key and using the provided sourceId field). This ensures the rec_id is persistent when the SOR is updated with the latest outputs from your data product.
In the example below, source_A is the name of the source inside of the data product configuration. A record exists in that source with the primary key value of 1234.
{
"data": {
"first_name": "John",
"family_name": "Doe"
},
"sourceId": {
"sourceName": "source_A",
"sourcePrimaryKey": "1234"
}
}Understanding record creates and updates
- New records are created in both the SOR, via the search then create or update record API call, and in the source dataset for the data product for the purpose of batch enrichment and clustering. The
rec_idof the record in the SOR is persistent and is not deleted when the batch data product is run. - Retired
tamr_ids(golden record IDs) are available in the record history and can be used in search. - The search then create or update record API call creates new records if no match is found.
- The search then create or update record API call updates a record if a match is found. It updates only attributes in a record where the value is null (the new values will only be added). Otherwise the update will happen after the next data product refresh, taking into account the data product’s consolidation logic.
Step 4: Orchestrate the Pipeline
Orchestrate the pipeline to perform the following tasks in order. Each of these tasks can be run using the Job API create operation. See the Jobs API documentation for more information on running each of these jobs.
- Refresh the sources in the data product. This job requires the
sourceIdfor the source, which is available on the Configurations > Sources page. - Update (refresh) the data product. This job requires the
dataProductIdfor the data product, which is available on the Configure Data Product page for that data product. - Update the Tamr RealTime SOR. This job requires the
workflowId, which is available on the Configurations > Workflows page. - Publish the data product outputs. This job requires both the
dataProductIdand thedestinationId. ThedestinationIdis available on the Publish page for that data product. - Publish the SOR mapping table. This job requires the
destinationIdfor the destination, which is available on the Configurations > Destinations page.
Step 5: Configure a Webhook
Tamr’s event-driven notification system enables you to keep all of your systems up to date with the golden records in the RealTime SOR. This system can publish Realtime notifications for authoring events to a user-specified endpoint (a webhook).
See Using Tamr RealTime Event Notifications for more information on configuring and using a webhook to monitor these events.