
Understanding Clustering
For each data product, Tamr Cloud uses a trained machine-learning model and any user-defined rules to identify and cluster source records that refer to the same real-world entity. For each cluster, Tamr creates a single entity (a company, contact, patient, and so on) with the most appropriate values from the clustered records. These entities are referred to as golden records.
Clustering:
- Uses the trained model to cluster records based on similarity of key attributes.
- Applies any rules to match or split those clusters, based on matching or non-matching values for specific attributes.
- Finally, applies any changes you have made as part of curation. See Adjusting Mastering Results to learn more.
Clustering Model
First, similar records are clustered together by the trained machine learning model.
Models are data product specific, and are trained to accurately identify similar companies, contacts, patients, and so on. Each model considers the similarities of values for relevant attributes for the data product to determine which records should be clustered together.
To learn more about the clustering model for your data product, refer to the data product documentation.
Clustering Rules
After the records have been clustered by the model, any user-defined clustering rules are applied to refine the results. Clustering rules deterministically identify records that should or should not be clustered together based on values in specific attributes that reliably indicate unique entities.
Types of Rules
A match rule matches clusters with matching non-null values for specified attributes, such as a trusted_id. Match rules will not match clusters that contain only null or empty values for the specified attribute.
A split rule splits clusters that contain records with different non-null values for specified attributes. The rule splits the cluster so that each new cluster contains records with matching values for the attributes.
Rule Priority
Most data products include multiple rules, which are listed in descending order of priority. Rules with higher priority will take precedence over other rules if there is a conflict in the clustering logic.
Identifying Applied Clustering Rules
On the Configure Data Product page, each rule is numbered. After the data product runs, the Applied Clustering Rules (clustering_metadata.applied_clustering_rules) attribute in the source records dataset provides the number assigned to any rules applied to the record and the rule type. This helps you understand the specific rules that determined the cluster for a given source record.
Note: After running the data product, the Source Records page also includes an Applied Rules attribute, which provides the internal zero-based number of the first applied rule. For example, if Rule 1 is applied, this attribute value is "0". The Applied Clustering Rules attributes provides more information about the clustering rules that were applied to the records.
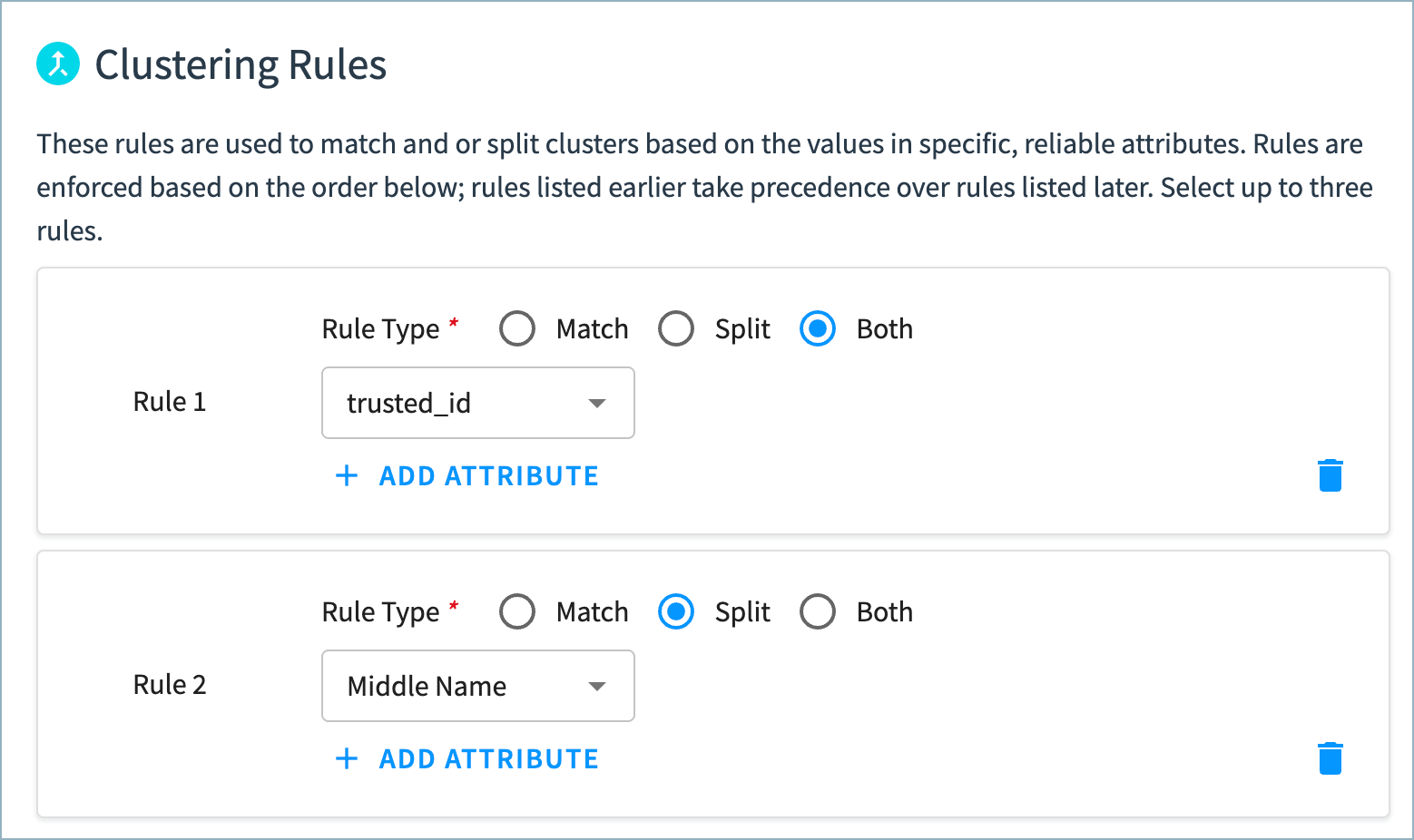
Clustering Rule Example
A Healthcare Provider data product includes a rule to always cluster together records with the same value for a customtrusted_id field, and to never cluster records with different trusted_id values. It also applies another, lower priority, rule that prevents healthcare providers who have different middle names from being clustered together.
Consider the rules in a Healthcare Provider data product, that are listed in this priority order:
- Match and split on
trusted_id: Records with matching values are clustered together; records with non-matching non-null values are put into different clusters. - Split on
middle_name: Records with non-matching non-null values are put into different clusters.
Here is how these rules are applied to a healthcare provider cluster:
- First, Tamr splits any records with different, non-null middle name values into different clusters.
- Then, Tamr splits any records in a cluster with non-matching, non-null values into different clusters.
- Finally, Tamr matches any clusters where records have the same trusted-id value.
This means that a record with a different middle_name value but the same trusted_id value will end up being clustered together, because the rule to match clusters with the same trusted_id has a higher priority than the rule to split on middle name.
Based on these rules, the records in the table below are grouped into 3 clusters as follows:
- Cluster A: Record 1, 2, and 3. These records are clustered together because:
- Records 1 and 2 have the same
trusted_id. Although themiddle_namevalues are different between the records, thetrusted_idrule takes priority. - Since Record 3 has a blank
trusted_id, it is included with the records with the most commontrusted_idwithin the cluster.
- Records 1 and 2 have the same
- Cluster B: Record 4. This record is put into its own cluster because:
- It has a different
trusted_idvalue than Records 1 and 2 and therefore is not included in Cluster A. - It has a different middle name than Record 5 and therefore cannot be clustered with Record 5 despite high similarity in other attribute values.
- It has a different
- Cluster C: Record 5. This record is put into its own cluster because it has a different middle name value than the other similar records.
| Record | Cluster | trusted_id | address_line_1 | city | first_name | last_name | middle_name | provider_specialty | region | Applied Clustering Rules |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | A | ab1cd2 | 123 Main Street | Springfield | Christopher | Rogers | Adam | Internal Medicine | OH | Rule 1 (Match) |
| 2 | A | ab1cd2 | 3 Spruce Ave. | Chris | Rogers | Arthur | Internal Medicine | MA | Rule 1 (Match) | |
| 3 | A | 123 Main Street | Springfield | Christopher | Rogers | Adam | Internal Medicine | OH | ||
| 4 | B | ef3hi4 | Main St. | Springfield | Chris | Rodgers | Adam | Internal Medicine | OH | Rule 2 (Split) |
| 5 | C | 123 Main Street | Springfield | Chris | Rodgers | Brian | Internal Medicine | OH | Rule 2 (Split) |
Updated 2 months ago