
Contacts Data Product
You use the contacts data product to master marketing data commonly stored in customer relationship management (CRM) software, such as B2C and B2B contacts.
This data product provides a 360-degree view of your B2B or B2C contacts, and ensures that you have the most complete and up-to-date information for each contact.
This data product provides:
- An industry-standard schema for B2B and B2C contact data.
- A machine learning model that deduplicates entities within, and across, your data sources.
- Data quality services for each contact's first name, address, phone, and email data.
Contacts Data Processing
The following diagram explains how your source records are prepared for clustering, and how Tamr creates and enriches the golden record for each contact.
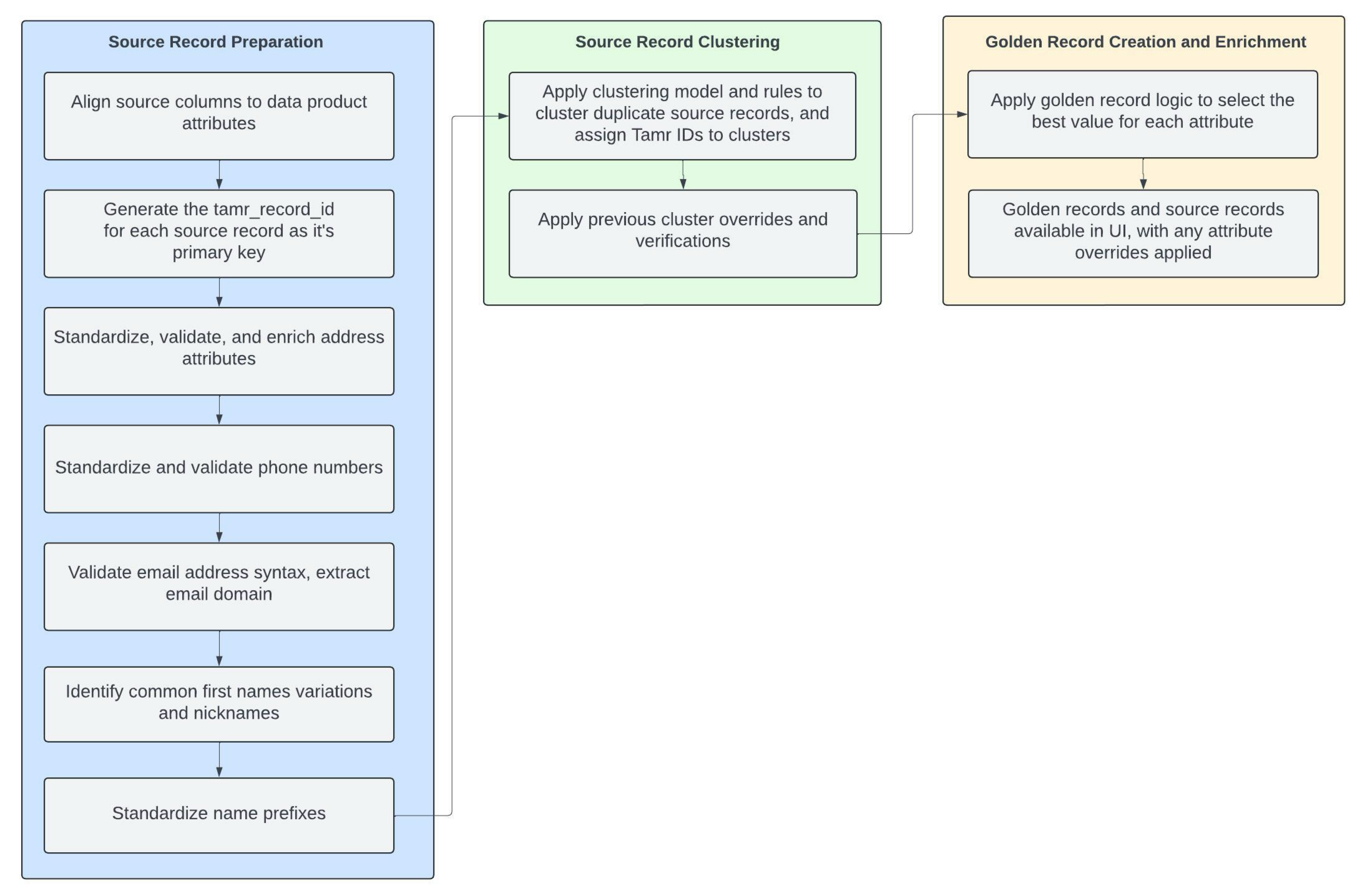
Source record preparation includes:
- Aligning source columns to data product attributes.
- Cleaning, validating, and enriching source record values. This includes cleaning for any specified bad values. These enhanced values provided by the data quality services are used as input when creating your golden records.
- Assigning each record a unique primary key, the
tamr_record_id. This ID is a 128-bit hash value of the source dataset name and the source primary key.
Source record clustering includes:
- Applying the clustering model and any clustering rules to group source records that refer to the same contact. (This model is described in the section below.) Each record in a given cluster is assigned the same Tamr ID. This ID is a unique, persistent identifier that links records in a cluster with each other and with the generated golden record for that cluster.
- Applying any previous cluster overrides and verifications.
Golden record creation includes applying logic to select the best value for each golden record attribute, and associating a Tamr ID with the golden record.
Contacts Clustering Model
By default, the contacts model groups records based on similarities between values for these attributes:
- Name, including common first name variations and nicknames
- Addresses (matches across primary, office, previous, mailing, and registered addresses)
- Phone numbers (matches across all phone number attributes)
- Personal email address
If provided, the LinkedIn URL also informs clustering.
Additionally, Tamr applies any custom clustering rules you have added to for the data product when clustering source records.
Data Quality Services
This data product includes these data quality services:
- Address Standardization, Validation, and Geocoding. This service examines values for the template's address attributes, and adds any resulting validated, standardized values to each record in new enrichment-specific attributes.
- Phone Enrichment. This service validates and standardizes phone numbers, and enriches phone numbers with type, carrier, and region.
- Email. This service validates the syntax of the email address and extracts the email domain.
- First name. This service examines first name values, and, for clustering purposes only, identifies common first name variations and nicknames. For example, common variations for Robert include Rob, Robbie, and Bob. The clustering model uses the original first name value and the enriched values when evaluating first name similarity.
- Name Prefix Standardization. This service improves match results by standardizing approximately 300 prefixes, such as Miss, Mister, Doctor, Engineer, and so on, to common abbreviations, such as Ms., Mr., Dr., and Eng.
See the linked topics above for processing details and added attributes.
Using this Data Product
To learn more about this data product's requirements, processing, and resulting mastered entities, see:
Updated 7 months ago